
Optimizing the training plan for the individual athlete.
Alan Couzens, M.Sc.(Sports Science)
Sep 14, 2018

I received quite a few follow up questions after my last post on determining whether you are a volume or intensity ‘responder’. The questions had a common theme – “OK, so I’ve worked out what category I belong to. Now what?”
In other words, how do I use this information to come up with a better training plan?
And this is the crux of coaching, isn’t it? Fundamentally, our job is less one of categorization or prediction and more one of optimization.
I would argue that being able to say to an athlete “See, I predicted that your performance was going to suck on your current training plan and, sure enough, you sucked!”, while it might make you a decent soothsayer, doesn’t make you much of a coach! :-) Prediction only takes us half the way because our job goes beyond looking ahead. We want the ability to look ahead into the future and then *change* the current plan to create the best likely outcome. This whole process of coming up with the best current plan to maximize future reward is called optimization.
And, it represents a whole field of data science in its own right. There is a great chapter on optimization in the book “Data Smart” that sums up the differences between predictive modeling and optimization perfectly using the Coca-Cola company's foray into creating the perfect (high taste, low cost) juice blend as a case study…

"Blend juices with complementary strengths and weaknesses to get exactly the right taste for minimum cost and maximum profit." Sounds similar to our own task of weighing the various volume/intensity 'ingredients' to get maximal performance for minimal cost/risk doesn't it?
This particular branch of analytics termed optimization had its start in the trenches - literally! Developed by the Soviet military in the 1930's to optimize resource allocation to its far flung troops & maximize damage to the enemy. Currently, its most extensive use is in the similar resource allocation domain of 'business intelligence'. However, it doesn’t take much of a leap to see how this relates to our own resource allocation task of coming up with the best “blend” (of volume, intensity etc.) to get the maximal ‘output’ (performance) on the minimal (time/energy) cost and how it could directly benefit our 'coaching intelligence' in coming up with the optimal plan for individual athletes. And, of course, as last week’s post suggested, this ‘right blend’ is going to be very different for different types of athlete.
Again from 'Data Smart'…
"Optimization is the process of mathematically formulating a problem and then mathematically solving that problem for the best solution."
So, let’s get to the nitty gritty of mathematically formulating our own particular ‘problem’ of maximizing athlete performance return on minimum time/energy investment so that we can solve it to find the best possible solution for a given athlete…
And, fortunately, the math isn't too painful at all. Because, (of course) my beloved Python has a module that does most of the heavy lifting for us – SciPy’s ‘optimize’.
With just 13 lines of code, we can calculate the optimal performance model for a given athlete…
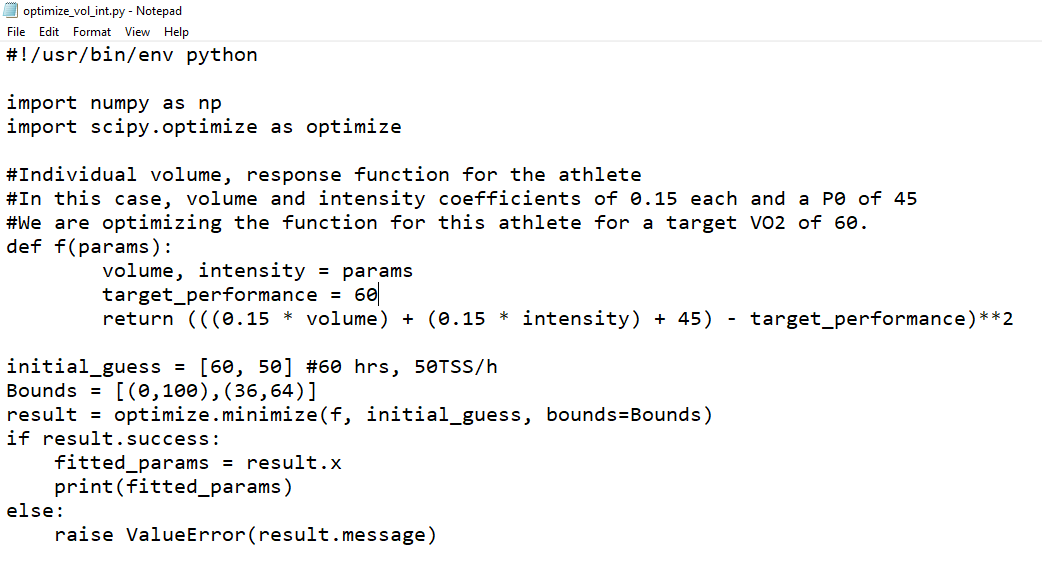
We simply pass a function that we wish to minimize. In this case, load minus performance, i.e. we want that gap between load and performance to be as small as possible. We want the performance number as high as possible with the load numbers as low as possible (for a given athlete). From the script above this is represented as…
((0.15 * volume + 0.15 * intensity + 45) – 60)^2)
Here, we give the function a target level of fitness (VO2 of 60ml/kg/min) along with athlete’s individual volume and intensity coefficients & intercept (45 ml/kg/min) from last week’s post. We then subtract our target performance level away and raise to the power of 2 so that the minimize function can’t return a negative.
We offer an initial guess to get the process started, along with the range of volume/intensity that we will accept (/that the athlete has time & energy for)
Then we set scipy.optimize ‘s (L-BFGS-B) minimize solver to work to come up with the smallest volume and intensity numbers that will satisfy the equation. In this case it returns…
[55.00, 45.00]
i.e. for this athlete 55hrs/mo at 45TSS/hr. (an I.F. of 0.67) is the optimal volume/intensity combo to get to a performance level (VO2 score) of 60.
If we apply the same script to a different athlete, a 'low responder' to volume, with a volume response coefficient of 0.1 and run the script again...
[64.60, 56.92]
...the computer tells us it will take this athlete ~65hrs to get to that same target level of performance.
Finally if we change the target_performance line for this low volume responder to a more ambitious 65ml/kg/min, and run the script again...
[100.00, 64.00]
It maxes out the bounds and tells us that it will take this athlete at least 100hrs at 64TSS/hr to reach that level of performance! Which makes total sense if we think it through - our max volume bound is 100hrs/mo, max intensity bound is 64TSS/h. The low volume responders coefficients are 0.1 for vol and 0.15 for intensity so..
0.1*100 + 0.15*64 + 45 =
10 + 9.6 + 45= 64.6
Max predicted VO2max of 64.6 (just short of the target of 65 even when max values are used)
Clearly by doing this, with each athlete’s individual performance model (ideally not manually as above ;-) it can help us take that next step beyond prediction to actually using the data to come up with the optimal plan to get a given athlete to a given level of performance.
In the example above, I’ve used a simple linear volume/intensity regression as my function of choice but you can pass any function that you want to minimize – a Banister model with the athlete’s individual k1, k2 coefficients or even something as complex as a multi-month neural network model! Which, as I suggested in this post is the superior model for most athletes.
However, the larger point of this post is that any mode, even a simple one like linear regression, that is optimized to the individual amounts to a huge step forward in the individualization of the training process!
By going through the process of optimizing an individualized model (vs a generic default or group model) – even a very simple one, we add a lot of practical planning power in coming up with the best possible training ‘recipe’ for a given athlete.
Train smart,
AC
TweetDon't miss a post! Sign up for my mailing list to get notified of all new content....